如何爬取网站
首先获取网址,通过模拟真实真实网页请求来获取网站的html文档。代码如下:
import urllib.request
url = "https://www.google.com"
headers = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.56"}
req = urllib.request.Request(url=weather_url, headers=headers)
html_encode = urllib.request.urlopen(req)
html_txt = html_encode.read()
html_txt = html_txt.decode('utf-8')
# print(html_txt)
html_encode.close()数据清洗
通过正则表达式筛选我们所需要的信息和剔除冗余信息。代码如下:
date = re.findall(r'<div class="th200">.* </div>', html_txt)
Date = []
for i in date:
temp = i.replace('<div class="th200">', '')
temp = temp.replace('</div>', '')
Date.append(temp)数据储存
将清洗好的数据通过Pandas存放在.csv文件中。代码如下:
import pandas as pd
data = pd.DataFrame([Date, Highest, Lowest, Weather, Wind])
data = data.T
data.to_csv('data.csv', index=False, header=False, encoding='utf_8_sig')多线程加速
代码如下:
from threading import Thread
thread_list = []
for yr in range(2012, 2022):
thread = Thread(target=get_year, args=(yr,))
thread.start()
thread_list.append(thread)
for i in range(10):
thread.join()
# time usage: 25.76s多进程加速
from multiprocessing import Process
process_list = []
for yr in range(2012, 2022):
process = Process(target=get_year, args=(yr,))
process.start()
process_list.append(process)
for i in range(10):
process.join()
# time usage: 25.30s多线程和多进程的利弊
多线程编程更加适合于I/O密集型任务的程序;
多进程编程更加适合于CPU密集型任务的程序。
因为网络爬虫的时候大部分时间都会用在网页的请求和相应上,因此多线程综合体验更优。对于Python来说,可能有人会说Python有GIL锁阻止多个线程在同一时刻运行,但是对于I/O密集型任务来说,等待网络请求阶段占据绝大多数时间,此时线程是会释放GIL锁的,因此线程间的锁冲突情况其实并不多。而多进程没有这个问题,理论上运行时间应该更快,但是多个进程占用的资源会很多,对于大型程序来说,线程的开销远远小于进程的开销,在性能差距不大的情况下,为什么不用多进程来节约资源呢?
全部代码
import threading
from urllib.error import HTTPError
import random
import urllib.request
import time
import re
def get_month(year, month):
weather_url = "https://lishi.tianqi.com/zhuhai/" + year + month + ".html"
headers = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.56"}
req = urllib.request.Request(url=weather_url, headers=headers)
try:
html_encode = urllib.request.urlopen(req)
except HTTPError as err:
print(err)
else:
html_txt = html_encode.read()
html_txt = html_txt.decode('utf-8')
# print(html_txt)
html_encode.close()
date = re.findall(r'<div class="th200">.* </div>', html_txt)
for i in date:
temp = i.replace('<div class="th200">', '')
temp = temp.replace('</div>', '')
Date.append(temp)
climate_sum = []
climate = re.findall(r'<div class="th140">.*</div>', html_txt)
for i in climate:
temp = i.replace('<div class="th140">', '')
temp = temp.replace('</div>', '')
climate_sum.append(temp)
num = 0
for i in climate_sum[4:]:
if num == 0:
Highest.append(i)
elif num == 1:
Lowest.append(i)
elif num == 2:
Weather.append(i)
elif num == 3:
Wind.append(i)
num += 1
if num == 4:
num = 0
def list_to_csv():
import pandas as pd
data = pd.DataFrame([Date, Highest, Lowest, Weather, Wind])
data = data.T
data.to_csv('data.csv', index=False, header=False, encoding='utf_8_sig')
def get_year(y):
y = str(y)
for m in range(1, 13):
time.sleep(1)
m = str(m).zfill(2)
print("Downloading " + y + "-" + m + " weather data...")
get_month(y, m)
def single_thread():
start = time.time()
for yr in range(2012, 2022):
get_year(yr)
end = time.time()
print("time:", end - start)
print(len(Date), len(Highest), len(Lowest), len(Weather), len(Wind))
def multi_thread():
thread_list = []
start = time.time()
for yr in range(2012, 2022):
thread = threading.Thread(target=get_year, args=(yr,))
thread_list.append(thread)
thread.start()
for i in range(10):
thread.join()
end = time.time()
print("time:", end - start)
print(len(Date), len(Highest), len(Lowest), len(Weather), len(Wind))
if __name__ == "__main__":
# Single-thread program
Date = Highest = Lowest = Weather = Wind = []
single_thread()
# Multi-thread program
Date = Highest = Lowest = Weather = Wind = []
multi_thread()
list_to_csv()
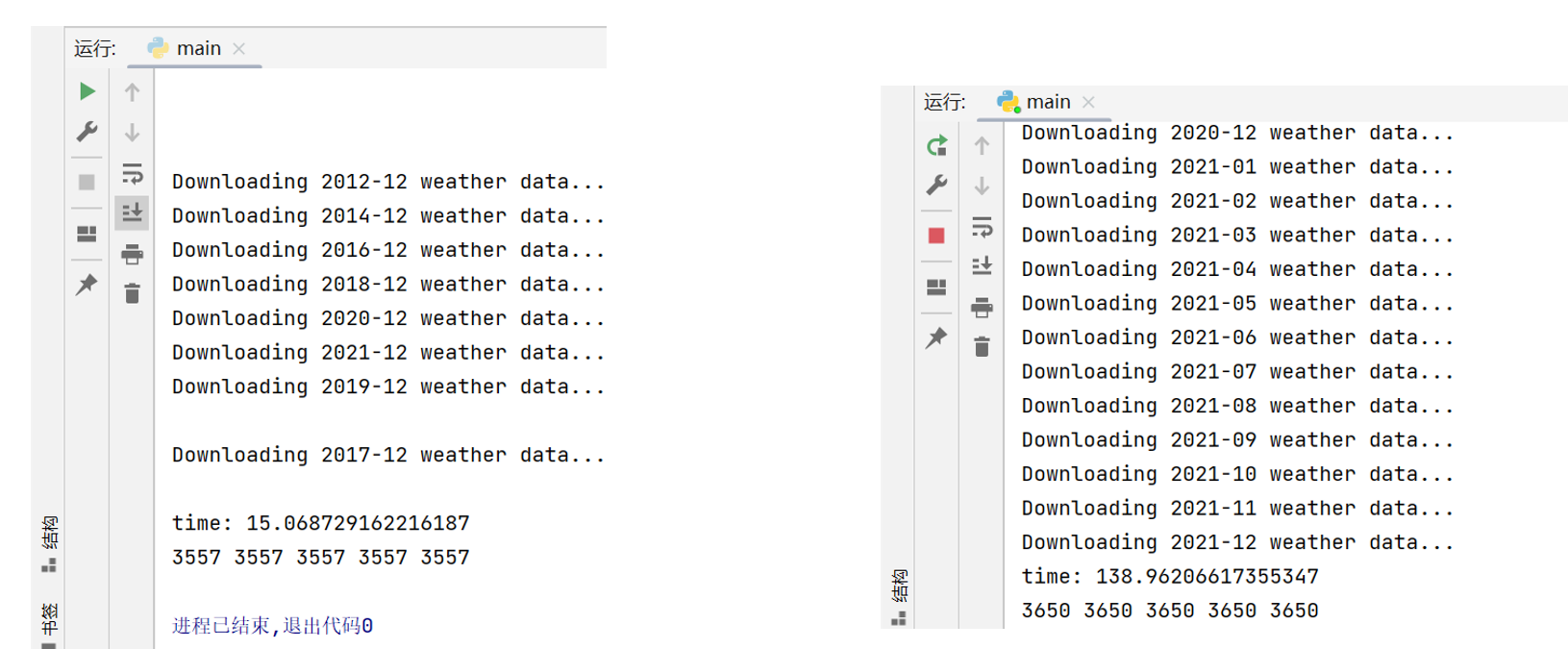
运行结果
左侧是多线程的结果,右侧是单进程的结果,多进程结果未截图,多进程与多线程对于此程序用时相近,单进程和多线程(本例为10线程)的时间差距在8-9倍左右,由此可以看出多线程的加速成绩对于网络爬虫来说是非常明显的。